A very fast BGRA to Grayscale conversion on Iphone

Almost all image processing algorithms uses gray scale images as input source. But almost all hardware video sources provide frames in RGB/BGR(A) formats. So gray scale conversion is very popular operation. Although it’s expensive enough to cause CPU-bound bottlenecks while running on mobile processors. In this post i will show you how to use ARM NEON intrinsic to get significant performance boost of BGRA to GRAY conversion.
Color representation

Pixel color can be presented in different ways. RGB color model presents color as a combination of three base colors of different intensity. Gray scale image contains only pixel luminance value without specific color. Pixels from RGB color model can be converted to gray scale using following formula: Y = 0.2126 R + 0.7152 G + 0.0722 B. Multipliers can very depending on the color space standards. Since we are targeting to iPhone it’s necessary to remember that camera capture from iOS AVFramework provide video frames in BGRA format (alpha channel is always equals to 255). For our further steps we will ignore it.
Implementation:
First of all we need reference C++ implementation. Just to know the starting point. Here it is:
Reference C++ BGRA to Grayscale conversion function:
| |
Okay, this function works relatively fast but not enough. Since iPhone has ARM CPU (Cortex A-9), it supports SIMD NEON engine which can be used for color conversion with great effort. SIMD technology allows process multiple data with one instruction call, saving time for other computations. Cutting a long story shorter – we will process eighth(!) pixels at one time.

Fortunately, you don’t have to deal with such low-level instructions directly. There are special functions, called intrinsic, which can be treated as regular functions but they works with input data simultaneously. If you want to learn more about NEON intrinsic you will found link in the “References” section.
ARM NEON Intrinsic-optimized conversion:
| |
This function process eight pixels per iteration. Great performance boost but I decided to go further and rewrite anything using assembler. This requires much more knowledge about CPU Architecture but result was worth of it.
NEON and Assembler:
| |
Results
I’ve done color conversion on 640x512 image (well-known graffiti image) 100 times to get more precise time measures. Here is a chart with graphical illustrations of BGRA to GRAY conversion using different algorithms. I’ve added two 3-rd party implementations (One from OpenCV – cvCvtColor, and one from Boost::Gil – copy_and_convert_pixels) to see how are they optimized. Testing hardware - IPhone 3Gs, iOS 4.2.
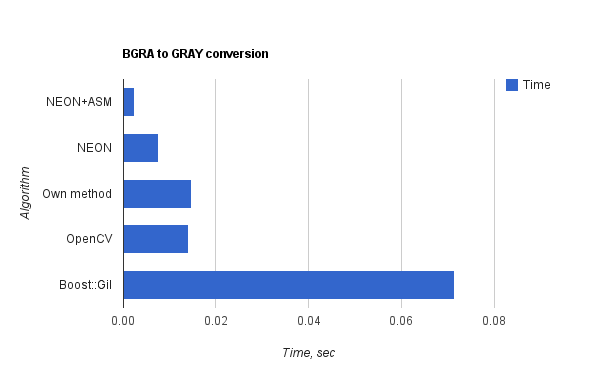
As we can see, NEON optimized assembler function works three times faster that C++ function with intrinsic and six times faster than pure C++ implementation.
References
Many thanks for the Nils Pipenbrinck. This article helps me a lot!